第三代> **注:** 本文转载自BeWater公众号: > https://mp.weixin.qq.com/s/HY2qKnTJBm0RKW9Da61deg 2021年9月4日,在BeWater DevCon 2021 全球开发者大会上,Avalanche 雪崩协议首席协议架构师和联合创始人 Ted Yin,他也是 Facebook 的 Libra/Diem 项目共识 HotStuff 论文作者,远在大洋彼岸的他视频连线,为大家带来了《Avalanche的实践与思考》的分享。 这场深度且系统的分享,引发了全场人的思考,核心观点: **1、2021 年的
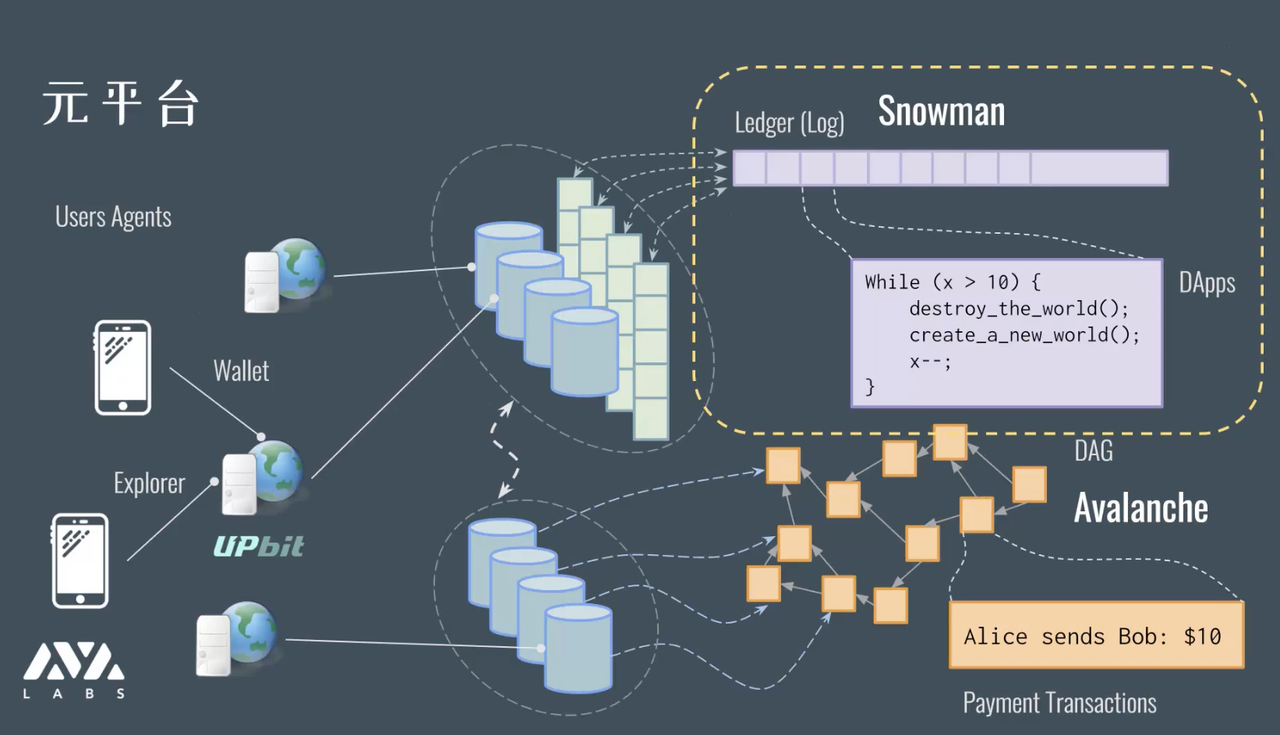
这里面不止会有一个真正意义上的链,而是有多个链作为子系统。
比方说有一个线性的链作为账本,有了线性序,我们就可以把计算和操作编码在这个 log 上面或 ledger 上面,就可以实现 dApp 或者标准的
优点1:工作量证明同时能作为准入机制 ——「Permissionless」
有一个很好的地方是工作量证明同时能作为准入机制,这是一个不容易理解的点。
大家经常说联盟链、公链,本质说的是一个准入机制:谁能进来玩?是不是任何一个人都可以来运行这个节点? 但其实准入机制和共识机制并不直接相关,只是中本聪设计的这个协议恰巧用了工作量证明,而这个工作量证明可以形成一个准入机制,也就是说,它不需要特殊的委员会,不需要审批过程,只要有算力,就可以挖矿,而且也不存在一个人可以通过控制节点数就能控制
为什么叫法老王的复生呢?这个东西研究了很久了,只是没有走进大众的视野,在传统的大公司里,如果接触过如 Paxos 和 Raft 这种冗余系统,那么会对 BFT 有点印象 —— 实际在 2000 年的时候,已经商用于宕机或机器崩溃时的冗余场景。
如果你有 f 个机器坏掉,那么只要还有 2f + 1 个机器就可以保持系统正常,比如Google 一般是 5 台机器。这种系统会高效且高可用,表现出来就是,我们现在所有的云服务能给大家一种 24小时 * 7 天不间断的假象。
在零几年的时候,很多网站还需要每个月维护一次或每周维护一次,但现在无需停机维护了,因此通过容错系统来遮蔽掉了这部分出错的机器。整个系统相当于一个大的数据中心,因为机器太多了,每秒钟都有机器坏掉,它会不断的更迭。这个角度来讲,它是好的系统,你可以想成使用了
在 13 年的时候有人抱怨看不懂这协议在干嘛,能看懂的就是客户端发送了请求,然后一个服务器给所有别的服务器广播说「hello」,然后这些服务器给所有的人发投票的什么东西,然后就是 maybe do some start,最后就是鬼画符,然后 definitely 了 —— 所以学术界懂这类算法的人也不多。
因此我们有一个结论,一对多或者多对多的广播,是非常糟糕的情况。
三、第三代
在我们打破这个问题之前,先纠正一个误区:
可能大家都觉得分片好,感觉像是救世主一样:随着分片技术的发展,「扩容难」已经过去了。
其实分片是在分布式系统或数据库领域的一个常见概念。所以如果跟不是搞
如果这个协议很垃圾,相当于汤本来就很难喝,分片相当于给汤里加老干妈,会变得好吃,但我们要知道,难喝的汤里加再多的老干妈,它也是有老干妈的难喝的汤。 
如果本来就是个火锅,汤底很好,我还是可以加辣的,就可以更好吃了。
第三代协议:Avalanche 协议
第三代并非意味着秒杀前两代,只是各自有特点。这套协议在具体的应用场景下,可以发挥很强的业务能力和性能。
一篇关于 Avalanche 的论文在 18 年 5 月被放到 IPFS 上,这篇论文是我们这帮科研人员合作的,受传染病模型(epidemic model)和流言(gossip)网络的启发。
第三代结合了前两代的优点:
1)有优雅的安全性的退化——不能说坏人到达一定的数量,网络就不安全了,直接崩溃了。
2)松散的成员信息——网络里面的节点数和名单不太一致,不会对大局观造成影响。
3)足够快——不因网络规模增加而线性甚至超线性的下降,如果是对数的下降就很好。
4)绿色环保
5)符合直觉—— PBFT 中的投票不符合直觉,太复杂了;中本聪共识很符合直觉,但又太慢了。
另一个被曲解的概念——TPS吞吐量
其它协议也说自己很快,有很高的吞吐量 (TPS:transaction per second 每秒钟交易数),但就像我们不会只看跑分结果买手机一样,吞吐量也是被曲解的概念。
如果你看计算机系统的论文,他们测性能,尤其是分布式系统绝对不会只测吞吐量,这个相当于在耍流氓。因为「吞吐量」只反应一个系统的负载缓冲能力,而「延迟」是反映真正响应用户请求的速度。
你作为一个用户不关心吞吐量— 每秒能服务几个人,用户更关心交易递交上去了,什么时候能上链,是一秒还是一小时?这个概念叫做「延迟(latency)」。
 评估整个系统不能只评测延迟,「吞吐量」和「延迟」这两者缺一不可。一个系统延迟可能确实很快,好像一个银行平常没有人来,只有一个或十个客户,那么延迟很低,但原因只是负载太低,没有什么用户在里面用,但如果有很多人排队,银行就招架不过来了,所以给定延迟的时候你要看吞吐量。
评估整个系统不能只评测延迟,「吞吐量」和「延迟」这两者缺一不可。一个系统延迟可能确实很快,好像一个银行平常没有人来,只有一个或十个客户,那么延迟很低,但原因只是负载太低,没有什么用户在里面用,但如果有很多人排队,银行就招架不过来了,所以给定延迟的时候你要看吞吐量。

如果不看延迟,只看吞吐量,会得到另外一个极端的研究。
跟互联网媲美的吞吐量是物流公司的吞吐量,比如我从北京寄一卡车的存储卡到上海,可能三天到货,按秒来算吞吐量是相当惊人的,但是你不能当网络用,也不会用这个东西做决策,所以不考虑延迟,只是谈吞吐量也是在耍流氓。
所以吞吐量和延迟两方面都要看。
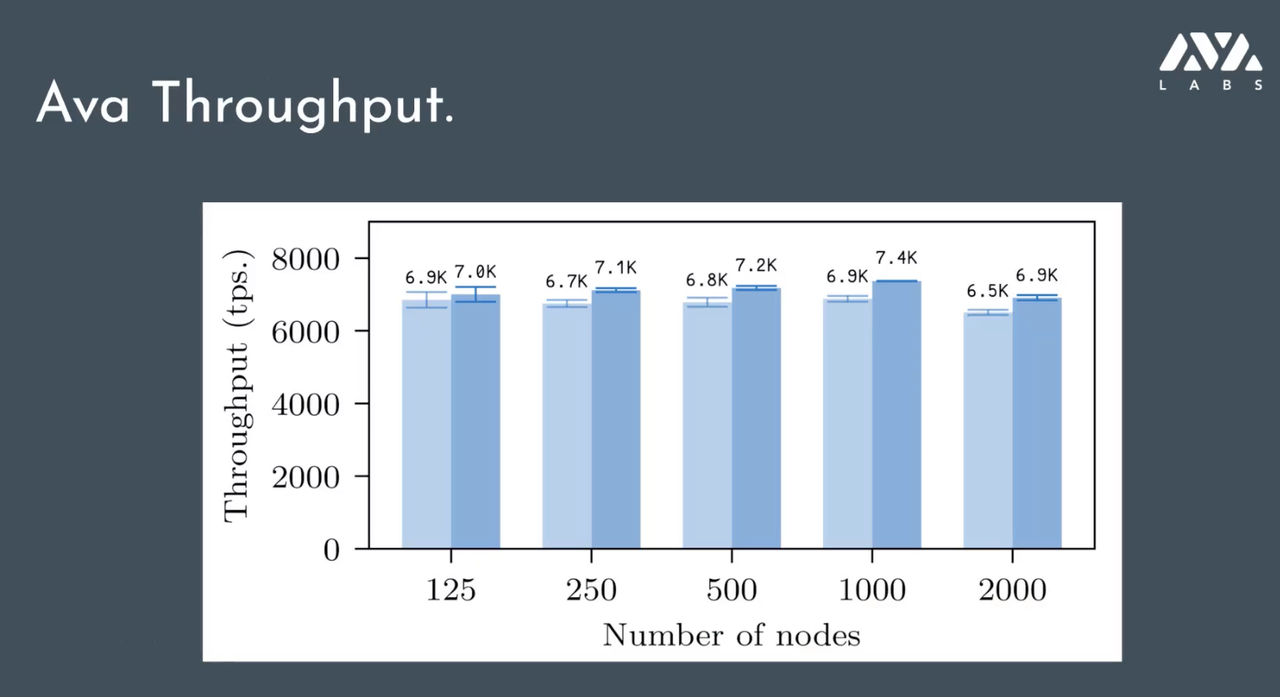
上图是节点数翻倍下 Avalanche 协议吞吐量的表现。在节点倍增的情况下,吞吐量受到的影响比较小,这里面也用到了一些别的技术,例如用 DAG 来实现并发交易。 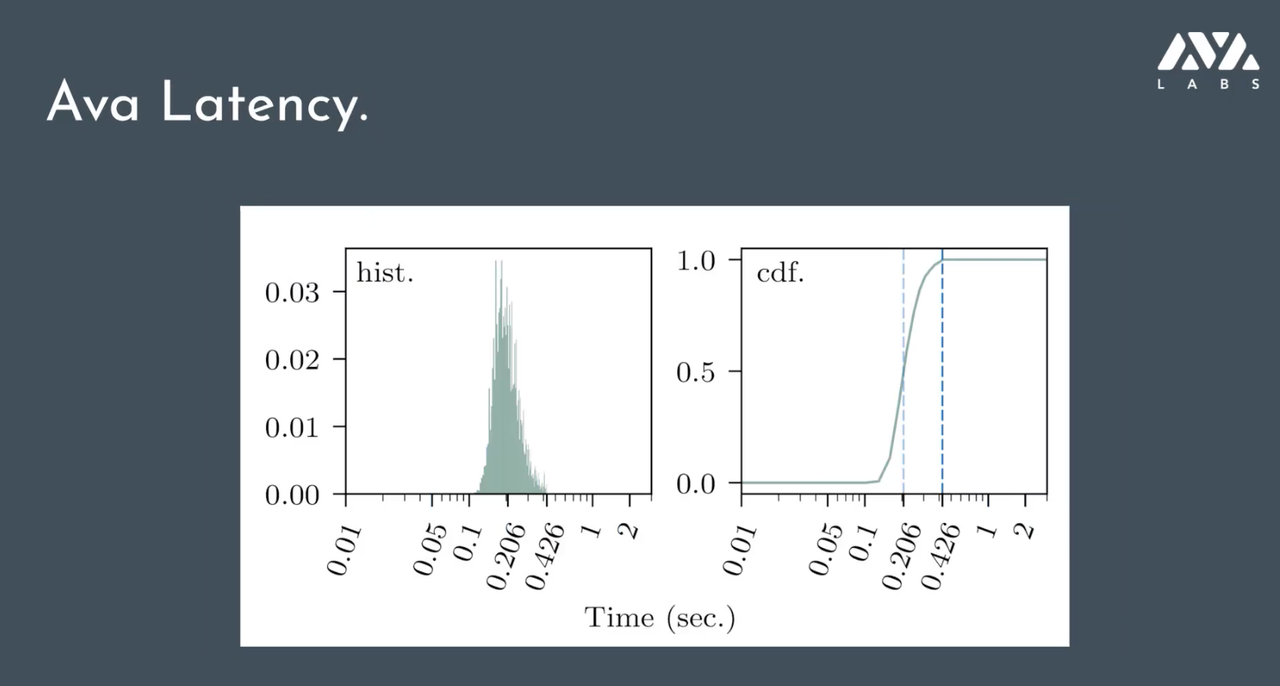
上图是在 2000 个节点的情况下,不考虑额外网络延迟的情况下做出的协议本底延迟。即使 2000 个节点都在投票,还是可以做到低于一秒的延迟——左侧即是延迟的分布。 
考虑实际的情况,把节点分散到全球 20 个城市,做完整的数字签名,使用比特币标准 UTXO 模型,结果还是相当客观,可以在维持每秒上千个交易的同时,保证一秒左右的确认时间。
如何实现?—— 流言网络作为共识本身
今天时间有限,我不能把每一步都展开。我从直觉的角度来给大家大致讲一讲主要思路是什么,凭什么?

如果有 N 个人在讨论娱乐圈的瓜是不是实锤,把真或假想象成一种决议,相当于上链或没上链。每个人独立的选 k(如 k = 10)个其它人,就算全国有上亿人也是选 10 个人,然后去看他们认为这个瓜包熟不包熟,真的还是假的。
张三根据他问的 k 个人决定自己对事实的倾向的确信度,张三的倾向又会影响到别人问他的结果。通过随机询问,信息在整个网络的可信度是上升的。 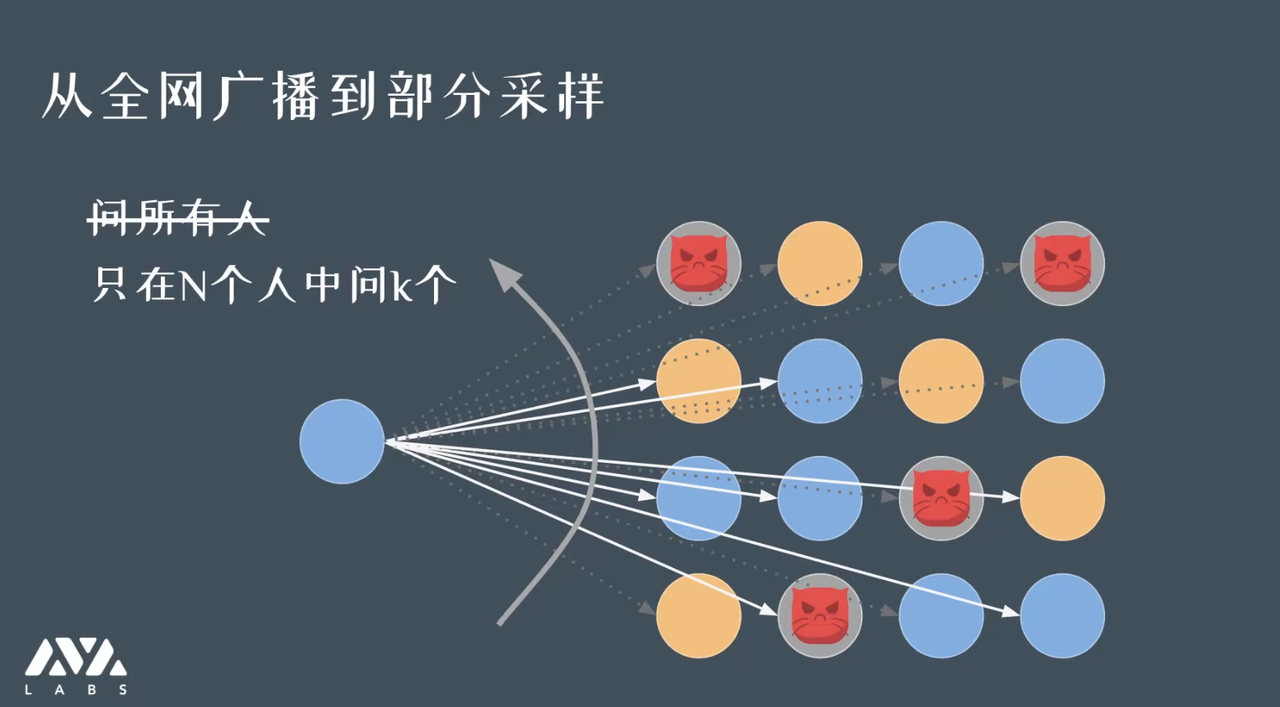
第三代协议相当于第二代协议的优势是不需要问全网所有人,只问一个随机抽样的群体,这个群体只跟安全性有关系,和网络的规模关系很弱。如我们有 100 万个节点,我们设定的 k 值依然可以是 10 或 20。
一个例子: 
这个例子里面,我们考虑每一个节点是一个颜色存在差异的圆圈。那可能张三原来觉得蓝色的表示实锤,橘色表示是假的。现在他认为是假的,他随便地问了五个人,发现有三个蓝色(实锤)。李四问了别的五个人,发现和张三意见相左。这个网络可能会在短时间震荡,但是微小的扰动就会让这个网络从
「震荡态」坍缩到「稳定态」——也即,所有的节点都成为同一个颜色。
这里有一个 Avalance 协议的演示 Demo:
https://tedyin.com/archive/snow-bft-demo/
我们会发现这个协议具有相当的鲁棒性。

协议特性总结:
1)我们只需要选一个小的样本,重复进行采样,无需工作量证明,也无需全局的投票。
2)好处就是网络有多快,过程就可以有多快,很容易扩容到大规模节点。
3)可以允许松散的成员。
4)引入任意的准入机制,如 PoS 机制。
四、元平台和子网链