
在这个理论证明中,我们证明了共识和计算的分离可以使得 PoS 本文翻译自Flow白皮书1-共识和计算分离,不带有个人观点。也不构成任何投资建议。 ### 摘要 现有
图 1:通过共识和执行节点的消息流概览。为简洁起见,仅显示正常操作期间的消息。惩罚请求被裁定期间交换的消息被省略 在本节中我们将进行理论推导,证明可以在不影响安全性的情况下将大部分计算和网络通信从共识节点分离。 Flow的设计确保在由执行节点引入的错误会具备四个关键属性: 可检测的:根据定义确定性过程具有客观正确的输出。因此,即使是网络中只有单个诚实节点也可以检测到确定性错误,并通过指出执行错误的部分来向其他诚实节点证明这个错误。 可追溯的:Flow 中所有确定性的输出必须被生成这个输出的节点进行身份签名。因此,已检测到的任何错误可以清楚地追溯到负责该输出的节点。 可惩罚的:Flow网络中的所有节点,包括执行节点和共识节点,必须进行权益(token)质押,如果被发现具有不利于正确共识达成或输出错误结果的行为,将对这些节点进行权益(token)扣除(因为每个行为都是可检测和可追溯的)。 可恢复:系统必须具有在检测到错误时撤销错误的方法。这将阻止节点进行收益大于被惩罚的恶意行为。 这样的设计一个重要特征是对于系统内部的每个操作都可以找到对应参与者负责。具体来说,除了共识节点之外的操作,从节点中选择一个子集负责执行,另外一个不相交的子集负责验证结果。下面简单介绍工作过程: 上述过程保证了恶意执行节点几乎可以肯定被惩罚。此外,恶意节点几乎不可能成功引入错误。 可能出现的一个问题是,为什么 Flow 具有独立的执行者组和验证者组而不是执行者来验证彼此的结果。我们通过这种分离解决验证者的困境。如果没有专门的验证者角色,执行者计算下一个块与验证(重新计算)之前块的结果之间存在利益冲突。在 Flow 中,这种困境通过专门的验证者得到缓解。关于验证协议的技术细节将在后续文章中介绍,其中包括了如何解决验证者不进行计算批准任何结果或验证者恶意标记正确的结果导致网络阻塞等问题。 以下定理介绍了Flow架构的安全保证并证明通过发布或批准错误结果将错误引入系统是经济的不可行。 定理 1(将工作委托给执行组和验证组从攻击成功的概率上看是安全的) 如果按照以下条件约束,则通过故意发布错误结果或验证通过错误结果将错误引入系统在经济上是不可行的。 需要强调的是,共识节点只需要检查是否有足够的节点执行并对其验证就足够了,他们不需要检测结果本身。定理1适用于任何具有确定终局性的BFT共识算法。 定理 1 的证明: 我们将证明定理1在符合以下条件时总是可以满足 具体来说,让我们考虑一组N个节点,我们希望从中随机抽取一个具有 n 个节点的子集。此外,我们假设最多有 M < N/3 个恶意节点。在下文中,我们将重点关注所有节点质押权益(token)均等的情况,即它们被包含概率是相同的。选中 m ≤ n 个恶意节点的概率由下式给出超几何分布 (译者注: (M m)可以认为等价于C(m, M)) 攻击成功的概率,P(successful attack),要求没有诚实节点,即全部选中恶意节点。因此 其中 Pn,N,M (n) 是正好全部选中恶意节点的概率 (译者注:这里的存在一些公式,简单推导下 Pn,N,M(m)=C(m,M)C(n-m, N-M)/C(n, N),当m=n=k时 Pk,N,M=C(k,M)/C(k,N)=(M!/k! (M-k)!)/(N!/k! (N-k)!)= M!/N! (N-k)!/(M-k)! 这里的C(m,n)是大家都学习过的求组合方式,C(m,n)=n!/m! (n-m)!) 上式(4)表明,仅选中恶意节点的概率随着n的增加而严格单调递减。也就是说样本量n越大,只选中恶意节点概率越小。 节点通过发布错误结果或批准错误结果来故意攻击网络,我们假设存在奖励r,如果它的攻击成功,节点会收到这些奖励r。但是如果攻击被发现,该节点将被惩罚ξ。 攻击网络所产生的期望收入为 为了使攻击在经济上可行,需要收入大于0 此外,式(4) 意味着 r/ξ 随着 n 的增加严格单调增加。当 n < N/2 时,r/ξ 随 n 呈指数增长。 式 (7) 的左侧 r/ξ 是安全性度量,因为它代表攻击系统的成本。举个例子,让我们考虑 N = 1000,M = 333,n = 10 的情况。为简单起见,假设对于发布或批准错误结果,该节点质押的全部权益(token)将被扣除。然后,为了攻击在经济上可行,成功奖励 r 需要是节点权益的 65343倍(译者注:由式7计算得来Pn,N,M=M!/N!(N-n)!/(M-n)!=333!/1000!990!/323!=(333…324)/(1000 … 991) r/ξ=(1000 … 991)/(333…324) – 1= 65343)。如果验证者每人质押 1000 美元,攻击者平均需要花费6530万美元覆盖质押被扣除的成本。当进一步增加n到 n = 20,攻击者需要花费 r/ξ = 5.2 * 10^9 倍质押权益(token)来发布错误结果。 总之,我们分析了将执行和验证委托给1个较多节点子集的结果。证明了通过发布或批准错误结果将错误引入系统在经济上是不可行的。这个结果适用于除共识节点外的其他节点。因此,共识节点只需要检查是否有足够的节点执行并对其验证就足够了,他们不需要检测结果本身。 定理1很关键,因为它允许我们: 其他节点以小组的形式相互验证,而共识节点以及共识委员会内部完成验证。 共识节点通过 BFT 共识算法确定事件的相对顺序。我们的结论适用于任何具有确定终局性的 BFT 共识算法,例如:HotStuff、Casper CBC或 Fantômette。 不同于其他节点的操作,共识节点在没有外部验证的情况下生成区块需要共识委员会的通过。区块的内容会被验证,如果发布的区块包含无效内容,共识节点将会被惩罚,但与其他操作不同(译者注:执行或验证)的是区块不会被重建。发布后外部各方可以检查最终确定的区块。但是,如果进行分叉攻击,双花攻击此时可能已经成功。为了提高整个系统的可恢复性,共识节点委员会应由尽可能多的质押节点组成。 对于一个简单的 BFT 算法,每个块的消息复杂度 η(所有 N 个节点发送的消息)为 O(N^2) 。更高级的协议实现O(Nlog N)或 O(cN),c是常量。整个共识委员会的总带宽负载 B[MB/s]为 B = β b * η β是整体网络阻塞率, b为消息大小 MB/s。 对于接收消息m并处理它的节点,增加延迟 L(m) = f(b) + process(m) 其中 f 表示接收 m 的网络传输时间, process(m) 表示处理 m 的计算时间。很明显,B 和 L 都很大程度影响共识算法的吞吐量。这高度依赖于选择的 BFT 协议,以及拓扑结构。其他因素包括延迟或带宽限制在底层网络硬件中。 目前,我们的目标是数千个节点的共识委员会。为了去中心化,应该是使得个人仍然可以运行节点并参与共识。因此,给定所需的网络阻塞率β和环境确定的函数 f,只有减小消息大小 b 或 process(m) 才能增加共识委员会中节点数量。 我们简要介绍如何同时减少 b 和 process(m)。各个过程的详细机制,请读者参考后续文章。 我们通过将我们的方法与 Vlad Zamfir提出的三角(译者注:这里三角是针对POS系统,因为要进行BFT投票所以低最终确定性延迟、低网络通信开销、多节点数量不能够同时满足,需要进行平衡)进行比较来结束本节(图2)。三角形表达了Zamfir对于POS系统的猜想。Flow通过将共识节点和执行节点进行拆分进行优化
1 介绍
3 理论性能和安全分析
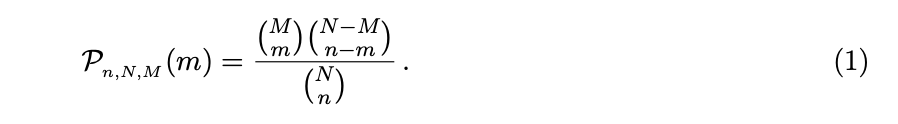
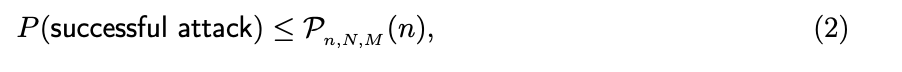
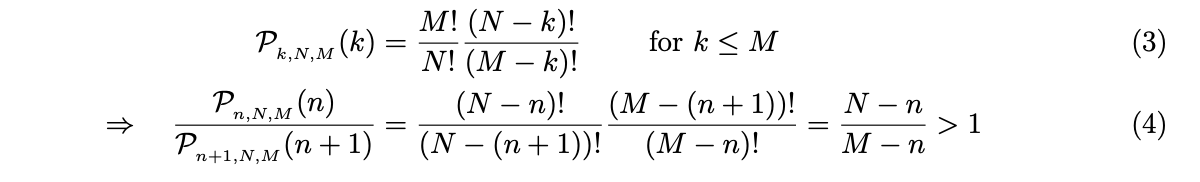
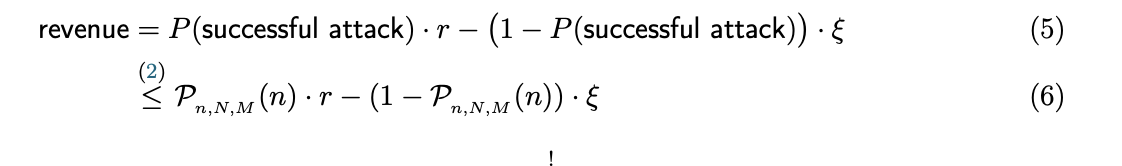

3.1 共识节点的特殊作用
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



